Mise en place d’un chantier d’ouverture des données au CMCQc
Ce deuxième billet a pour objectif d’illustrer la méthodologie de travail que nous avons utilisée et comment elle a été implantée au sein de notre pratique. À notre arrivée, nous avons pris connaissance des objectifs du projet : faire découvrir la musique de création des compositeur.trice.s du CMCQc en s’engageant dans une initiative d’ouverture de données et de partage de connaissances et d’expertises.
Comme beaucoup de projets numériques, notre démarche de travail s’est articulée en deux temps :
- Comprendre le fonctionnement des CMC : leurs pratiques, leurs données et leurs écosystèmes;
- S’approprier les concepts du web sémantique et les sujets connexes.
Cela nous a permis, d’une part, de prendre connaissance et de maîtriser nos données et d’autre part, de nous documenter afin de choisir le modèle et l’infrastructure technologique pouvant nous permettre l’ouverture de ces données. Dans les deux cas, il s’agit d’un long processus d’assimilation de l’information.
Voici les principales activités pour la mise en place d’une pratique de travail :
- Outils collaboratifs
- Création d’un espace en ligne et d’une bibliographie partagée; mise en place d’une veille technologique (logiciels de veille, réseaux sociaux, infolettres, etc.).
- Échéancier
- Élaboration hebdomadaire des objectifs avec un contrôle et un réalignement en fonction des changements.
- Autoformation
- Consultation d’un grand nombre de documents (articles, vidéos, livres, MOOCs, webinaires, etc.) sur les sujets suivants : web sémantique, données ouvertes et liées, modèles de données, ontologies et taxonomies; licences et droits d’auteur; bases de données relationnelles et graphes de connaissances; outils de visualisation, projets d’humanités numériques; Wikidata et autres projets wiki, etc.
- Apprentissages sur les CMC : à l’aide de documents sur place, des sites internet, mais aussi grâce à des échanges avec les compositeurs et employés du CMC National et du CMC Québec.
- Rencontres de professionnels :
- Participation à des formations et des séances d’informations en ligne.
- Rédaction hebdomadaire du travail accompli
- Courts rapports qui ont permis au conseil d’administration et à la direction de suivre nos activités tout en servant de base en vue de la rédaction d’une documentation de qualité.
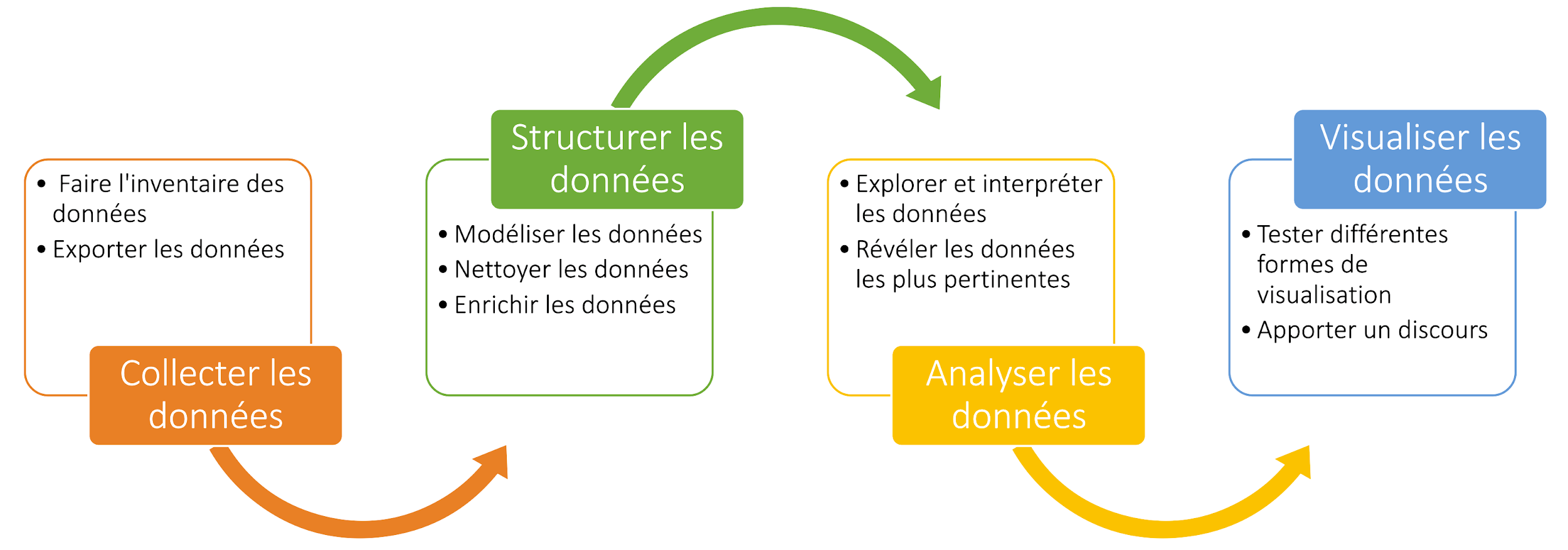
Traitement, analyse et visualisation des données
Après l’étude approfondie du CMCQc et de son fonctionnement, nous sommes entrés dans le vif du sujet en nous familiarisant avec les données. Ce travail de traitement et d’analyse avait un double objectif : étudier le flux de travail pour la saisie des données au CMCQc mais aussi identifier les différents types de données présents dans la base de données interne FileMaker.
- Le flux de travail pour la saisie des données au CMCQc;
- Réflexions sur la structure actuelle de la base FileMaker et sur son potentiel, mais aussi sur d’autres systèmes de gestion des données à des fins de comparaison et de projections;
- Rédaction d’un guide de règles de saisie : une mise à jour de ce qui avait été fait en mettant l’accent sur l’importance des métadonnées, en vue d’améliorer la qualité des données;
- La collecte de données
- Réalisation d’un inventaire de données à l’aide d’un tableau répertoriant l’intégralité des champs présents dans la base FileMaker (nom de la table, nom du champ, description du champ, type de données, commentaires ou observations et pertinence pour notre projet);
- Tests d’exportation des données : développement en interne d’un outil de recherche pour être en mesure d’exporter les données nécessaires au projet en trois fichiers au format CSV (compositeurs, œuvres et formations)
À noter, les sections suivantes feront l’objet de futurs billets de blogue afin de communiquer et de partager notre expérience de travail plus en détail : échantillonnage, modélisation et visualisation des données.
- Structurer et analyser les données
- Élaboration d’un modèle de données en fonction des besoins de l’institution en vue d’une ouverture dans le web de données
- Nettoyage des données exportées à l’aide du logiciel Dataiku : constitution d’un échantillon de données comprenant 84 compositeurs avec, comme informations requises : nom, prénom, genre, date naissance et mort, lieu d’études, ISNI, etc. Cette étape nous a aussi permis de quantifier le pourcentage de données saisies par champ pour ensuite mettre en place une stratégie d’enrichissement des données
- Enrichissement des données : tout d’abord, à l’aide d’un travail dans le service de requête SPARQL de Wikidata, nous avons récupéré les compositeurs québécois agréés au CMCQc afin de procéder à une réconciliation des données (alignement des données avec Wikidata). Ensuite, nous avons entrepris des recherches pour compléter les données manquantes à partir de diverses sources (encyclopédies en ligne et sites Web sur la musique de création) afin d’obtenir un échantillon de qualité.
- Visualisation des données (expérimentations avec deux outils de visualisation de données) :
- Palladio : utilisation de diverses visualisations (carte, ligne du temps, graphe, etc.) pour donner un aperçu du travail qui peut être fait avec les données du CMCQc (les naissances et morts par genre, la répartition des compositeurs en fonction de leur lieu de naissance et/ou lieux d’études, etc.)
- Gephi : proposition de visualisations des liens entre les compositeurs, plus particulièrement les liens professeurs/élèves
Réaliser un projet à sa portée
En définitive, nos objectifs de base sont restés essentiellement les mêmes, c’est à dire : approfondir les connaissances numériques de l’équipe du CMCQc et améliorer la visibilité de la musique des compositeur.trice.s québécois.es. Toutefois, avec les changements imposés par le confinement et à la lumière de nos essais/erreurs, de nos apprentissages et de nos constats, nous avons pris des décisions quant à la finalité du projet. Voici nos principales réflexions :
- Collaborer : l’une de nos forces a été d’être une petite équipe favorisant ainsi la communication et la flexibilité. De plus, ayant chacun nos propres domaines d’expertise (développement informatique, musique et modélisation/analyse des données), nous avons été à même de mettre en place une méthodologie de travail et de réagir rapidement pour réviser nos objectifs
- Planifier des activités d’échanges et de partage d’expériences avec nos partenaires : normalement prévues à mi-parcours de cette année exploratoire, ces activités n’ont pu avoir lieu comme prévu, puisque nous étions rendus en confinement
- Travailler en contexte de confinement : comme beaucoup d’institutions, notre travail a été affecté par la pandémie et nous avons dû faire preuve d’originalité pour continuer. N’ayant pas accès à distance à la base FileMaker, nous avons pris le parti de créer un échantillon en croisant les données issues de Wikidata et celles du système intégré de gestion de bibliothèques (SIGB) Sydney du CMC National. S’en est suivi une phase d’expérimentations qui nous a aidés à prendre conscience du véritable potentiel d’interconnexions des données du CMCQc. Le résultat est double :
- État des lieux des fiches compositeurs québécois agréés au CMCQc présents dans Wikidata
- Expérimentations en visualisation de données : autoformation sur les outils utilisés ; cela nous a permis de faire ressortir les liens abstraits entre nos concepts et de leur donner un sens : une proposition imagée fait parfois une meilleure démonstration qu’un document textuel.
- Prendre le virage technologique : à travers nos recherches et au vu de nos résultats d’expérimentation, nous avons pris la décision d’utiliser Wikidata comme infrastructure technologique pour ouvrir nos données.
Finalement, comme tout projet, nous avons révisé de façon itérative nos actions sans perdre de vue notre objectif premier : donner de la visibilité aux compositeur.trice.s agréé.e.s au CMCQc.
Il faut savoir qu’à l’origine, nous avions l’intention d’utiliser les possibilités offertes par le web sémantique. Toutefois, notre pratique de travail nous a fait réaliser qu’une meilleure connaissance de nos données et de nos besoins sont les paramètres structurants et déterminants à la réussite d’un projet.