Dans le cadre du projet exploratoire sur la musique de création et le web sémantique, le contexte particulier de pandémie de l’hiver 2020 ne nous a pas freiné; au contraire, ce fut l’occasion de prendre le temps d’expérimenter. Au début du confinement, n’ayant pas toujours eu accès aux données de la base FileMaker à cause du télétravail, nous avons pris le parti de constituer un échantillon de données à tester. À travers ce billet de blogue, nous souhaitons vous faire part des réflexions qui ont mené à la réalisation d’un échantillon de données, des différents outils utilisés et des enjeux de visualisation de données.
Pour illustrer notre processus de travail, voici les différentes étapes :

Modélisation des données
Nous avons réalisé un travail préparatoire en deux temps :
- Réalisation de l’inventaire des données présentes dans la base de données FileMaker;
- En fonction des besoins du CMCQc, nous avons créé un modèle de données en vue d’une ouverture des données. Pour ce faire, nous utilisons Wikidata afin de montrer le potentiel de ces «?liens invisibles?» entre les données du CMCQc et le Web de données.
Modèle de données
Dans un deuxième temps, nous avons constitué le dictionnaire de données du CMCQc tout en gardant à l’esprit ses besoins, mais aussi ceux des futurs utilisateurs.

La modélisation (méthode Merise)
Plusieurs méthodes ou langages permettent la réalisation de cette modélisation, faisant partie intégrante du processus de conception d’une base de données ou d’un modèle de données, comme la méthode Merise ou le langage de représentation UML.
Élaborée en France dans les années 1970, aux suites des travaux d’Hubert Tardieu (2003), la méthode Merise permet l’analyse, la conception et la réalisation de systèmes d’information.
Basée sur le principe de séparation des données et des traitements, elle se décline en trois niveaux :
- Le niveau conceptuel : modèle entité-association;
- Le niveau logique ou organisationnel : modèle relationnel;
- Le niveau physique : implémentation dans un système de gestion de base de données (SGBD).
Cette méthode est privilégiée, car les données ne sont pas d’une grande complexité, donc une modélisation simple et une implémentation rapide suffisent.
Dans ce sens, nous avons réalisé un modèle entité-association (niveau conceptuel) qui permet de schématiser les liens sémantiques entre une ou plusieurs entités. Une association est qualifiée à l’aide d’un verbe.
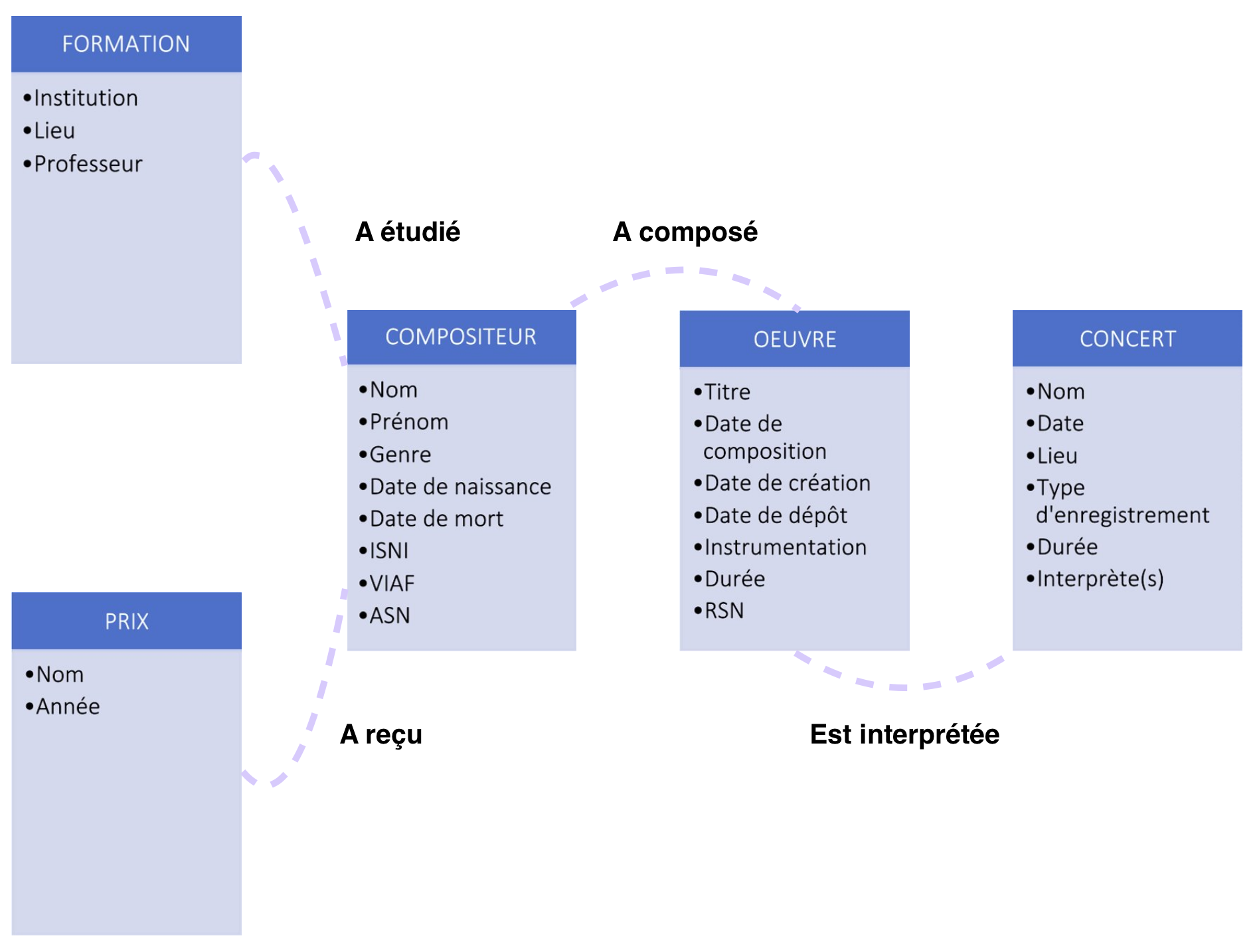
Échantillonnage des données
Cette tâche a un double objectif : d’une part, elle nous permettait de constater et d’analyser la représentation des compositeur.trice.s du CMCQc dans Wikidata et d’autre part, de constituer un échantillon de données afin de mener des expérimentations de visualisation des données.
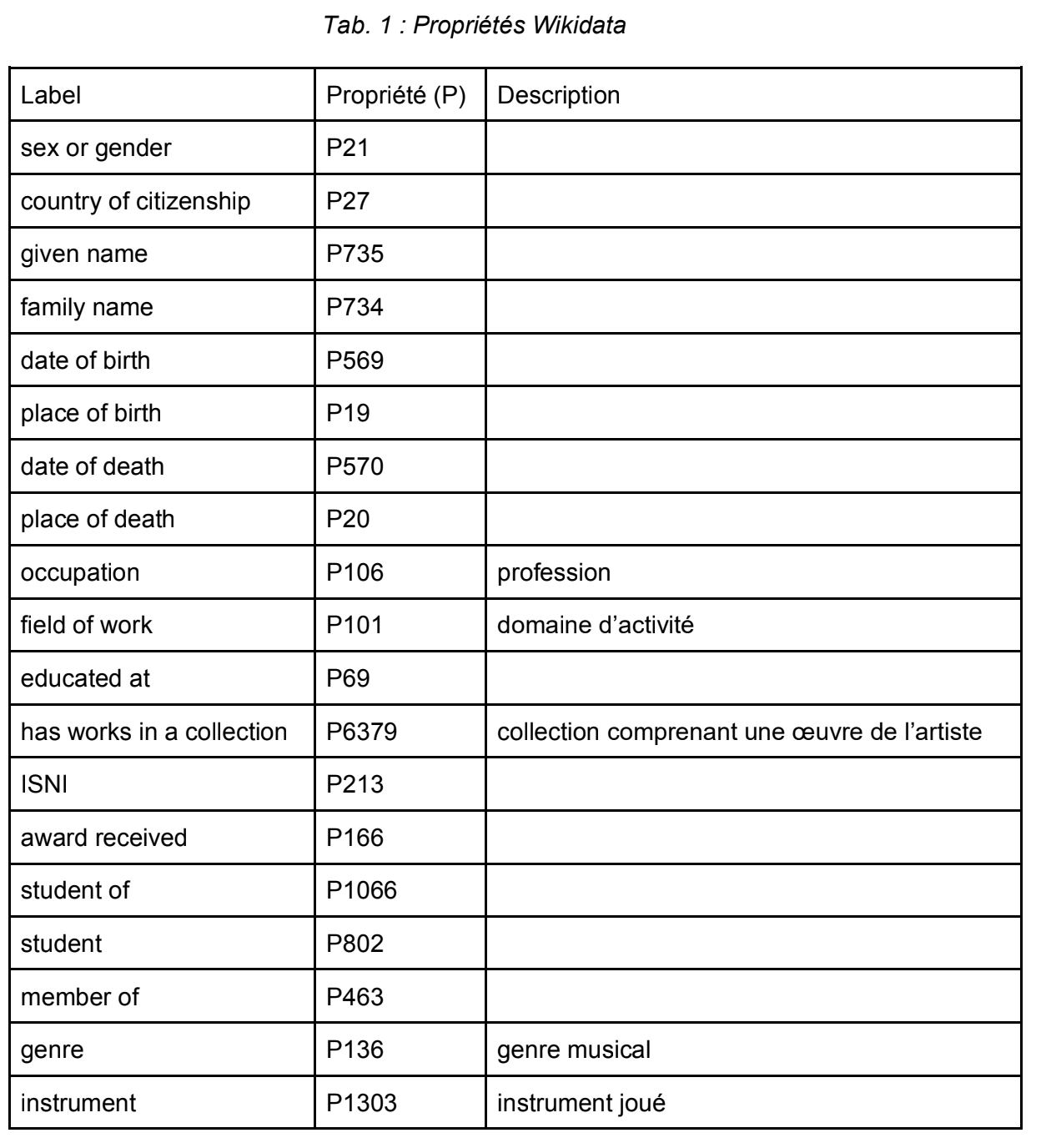
Identifier les données à extraire de Wikidata
À partir d’exemples de fiches « compositeur » dans Wikidata, nous avons identifié les propriétés nécessaires et en lien avec les données du CMC pour l’extraction de données.
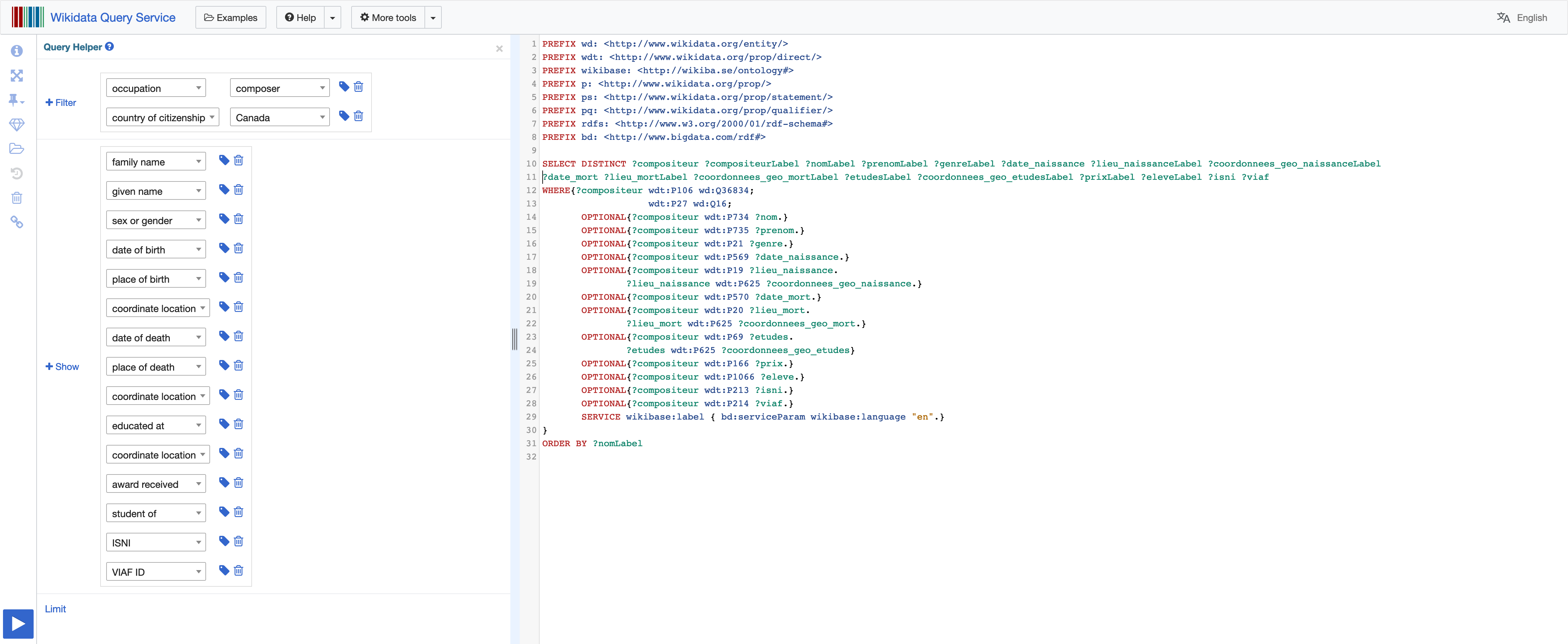
Interroger le service de requêtes de Wikidata
Nous avons interrogé et récupéré les données dans le service de requêtes SPARQL de Wikidata à l’aide d’une requête. Cela nous a permis d’obtenir une liste au format CSV de tous les compositeurs ayant pour occupation « compositeur » et pour nationalité « canadienne » dans Wikidata, soit 2168 entrées. Lors de ce travail d’extraction, nous étions conscientes que les compositeur.trice.s agréé.e.s au Québec ne sont pas forcément tous.tes de nationalité « canadienne », mais cela nous permettait d’obtenir un premier échantillon de travail.
Préparation de l’échantillon de données
À l’aide du logiciel Dataiku, nous avons appliqué plusieurs recettes afin de structurer le jeu de données constitué :
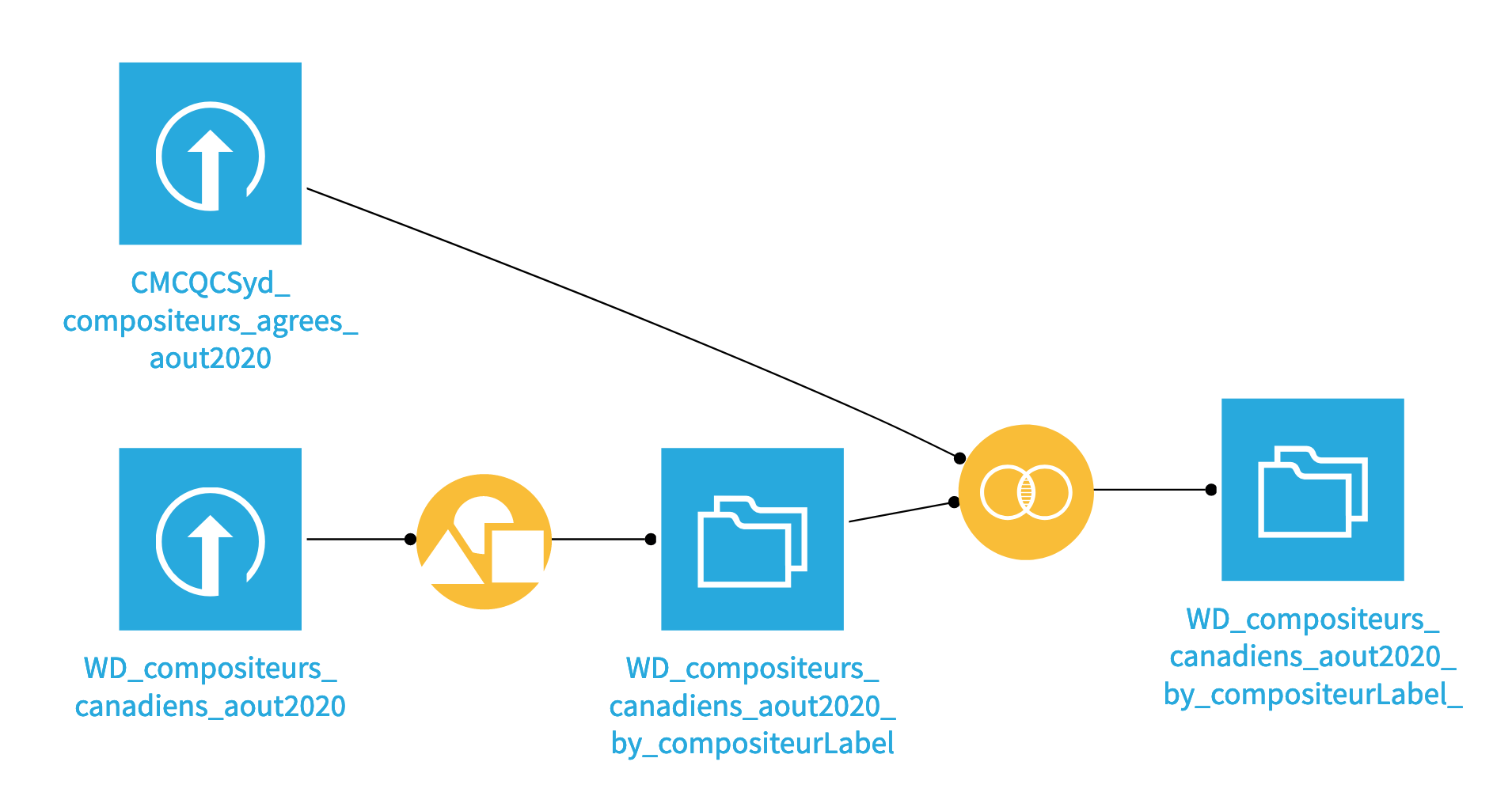
Group
Cela nous a permis de regrouper l’ensemble des données par clés (ici, les noms et prénoms des compositeur.trice.s)
Join
Nous avons fait une jointure entre deux jeux de données : le premier comprenait la liste des 236 compositeur.trice.s du CMCQc extraite de la base FileMaker et l’autre, les données issues de Wikidata. La jointure s’est faite au niveau des noms et prénoms des compositeur.trice.s, permettant ainsi d’obtenir un échantillon de données de 85 compositeur.trice.s affilié.e.s au CMCQc.
Structuration des données
- Nettoyer les données :
- Utilisation du logiciel Dataiku pour nettoyer et normaliser les données (par exemple, les dates de naissance et de mort : AAAA-MM-JJ);
- Enrichir les données :
- Fonction « réconcilier » avec OpenRefine : permet, sur une colonne choisie – en l’occurrence, les compositeurs – de réaliser un alignement des entités.
Pour une meilleure précision des matchs, nous avons pris le parti de faire manuellement l’appariement des données. Cela nous permet à la fois d’obtenir les compositeurs qui ont déjà une fiche dans Wikidata (140), mais aussi de faire, par la suite, un enrichissement des données présentes dans la base FileMaker (vérification et ajouts de données manquantes).
Nous avons procédé à une vérification et des ajouts d’informations relatives aux lieux de formation, aux professeurs et aux prix de 85 compositeur.trice.s du CMCQc. Pour cela, nous avons consulté comme principales sources :
- L’Encyclopédie canadienne
- Société de musique contemporaine du Québec
- electrocd
- Centre de musique canadienne
- Wikipédia
Visualisation des données
Une fois l’échantillon constitué et normalisé, nous avons testé différentes formes de visualisation : carte, graphe, etc. En voici, quelques aperçus :
Expérimentations de visualisation des données dans l’outil Palladio

Dans cette visualisation pour chaque compositeur, nous avons son lieu de naissance et les différents lieux où il est allé étudier (pour certains, le nombre peut aller jusqu’à 6 écoles ou universités). Utilisation de 7 filtres de visualisation : un pour les lieux de naissance (gris) et 6 pour les lieux d’études. Chaque filtre est relié au suivant, car il prend pour point de départ le précédent (par exemple : lieu de naissance vers lieu d’études 1 et lieu d’études 1 vers lieu d’études 2, etc.). Pour les lieux de naissance, la grandeur du cercle prend en compte le nombre de compositeurs nés à une même place.
Il s’agit de premières visualisations, mais c’est une excellente façon de rendre compte des écoles ou universités où sont allés étudier les compositeurs. Pour le moment, il n’est pas possible de savoir précisément quel compositeur a étudié où, mais à terme il serait intéressant de pouvoir suivre son parcours.
Expérimentations de visualition des données dans l’outil Gephi
Nous avons commencé par un travail sur deux fichiers CSV : un pour les compositeurs (label : nom et attribute : homme ou femme) et l’autre pour les relations professeurs/élèves (source : départ, et target : destination) pour qu’un traitement dans le logiciel soit possible. Malgré un temps de traitement long, un travail manuel a été privilégié, car il permettait de faire une vérification et donc de réduire les erreurs par rapport à un traitement automatique.
- Fichier compositeurs : nous avions pour base les 84 compositeurs extraits à partir de Wikidata auquel nous avons ajouté manuellement les professeurs et élèves afin de pouvoir leur attribuer un identifiant de nœud aléatoire et un attribut (homme ou femme). Cela nous a donné un fichier comprenant désormais 304 personnes.
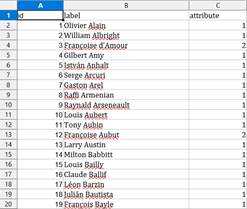
- Fichier relations professeurs/élèves : saisie manuelle des relations entre les professeurs et les élèves. Pour ce faire, nous avons utilisé les identifiants. Nous obtenons donc un fichier qui comprenait 368 relations.
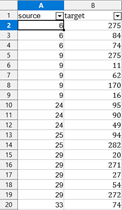
Une fois nos deux fichiers constitués, nous créons un espace de travail dans Gephi afin de faire les premiers tests de visualisation. Pour ce faire, nous avons utilisé différents filtres de spatialisation tout en spécifiant des paramètres communs à savoir :
- Distinction homme/femme : couleur bleu pour les hommes et rouge pour les femmes;
- Distinction des relations hommes/femme : couleur bleu pour les hommes, rouge pour les femmes et violet pour hommes/femmes;
- Affichage des labels;
- Épaisseurs des nœuds et des liens.
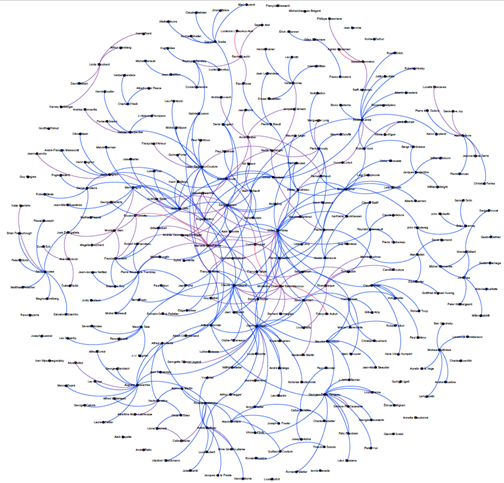
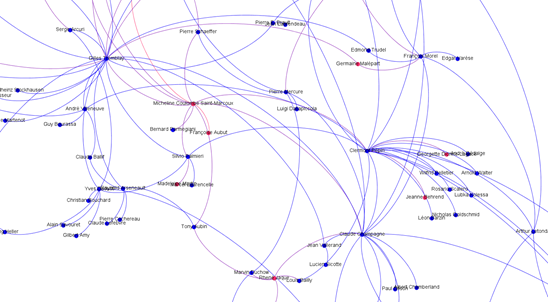
La visualisation du réseau des professeurs/élèves au sein des compositeur.trice.s du CMCQC se révèle pertinent. À première vue, il est possible de rendre compte de :
- La distribution hommes/femmes (88%–12%);
- Mettre en avant l’enseignement par l’utilisation de couleurs : d’un homme à un homme (bleu), d’une femme à une femme (rouge) et d’un homme à une femme ou inversement (violet).
En définitive, ce travail a été bénéfique à plus d’un titre :
- Nous avons obtenu une meilleure connaissance de nos données, et ce, en les modélisant en fonction des besoins du CMCQc, mais aussi de ses futurs utilisateurs;
- Nos expérimentations dans Wikidata nous ont permis tant de constituer un échantillon de données de qualité que de connaître la représentativité des compositeur.trice.s agréé.e.s au CMCQc (de nationalité canadienne, rappelons-le);
- Nous nous sommes familiarisées, mais aussi formés de manière autonome à divers outils comme le service de requêtes de Wikidata, OpenRefine ou encore Gephi;
- Grâce aux outils de visualisation de données que nous avons utilisés, nous sommes en mesure de faire ressortir les liens « abstraits » entre nos concepts et de leur donner un sens : une image fait parfois une meilleure démonstration qu’un document textuel.
N’étant pas des spécialistes de la visualisation de données, nous gardons à l’esprit que nos expérimentations ne sont que les prémices d’un projet qui se veut plus grand, notamment en interreliant les données dans le domaine de la musique de création québécoise et canadienne.